
Orchestration de Containers : Quelle approche pragmatique ?
L'orchestration de containers : quelles alternatives à Kubernetes ?
Chez Cantor, nous utilisons la technologie Docker depuis ses débuts.
Nous sommes très grands consommateurs de celle-ci, au point de « dockeriser » chacune de nos applications tant que possible.
En association avec Docker, nous utilisons également Ansible pour automatiser et centraliser le déploiement de nos applications depuis maintenant quelques années.
De ce fait, nous possédons à ce jour plusieurs centaines de conteneurs d’applications aussi bien pour des environnements de sandbox, de recette mais aussi de production.
C’est donc tout naturellement que nous nous sommes posés la question des technologies d’ orchestration de ces conteneurs.
Cette question est d’actualités lorsque l’on évoque la question d’un plan de reprise d’activité (PRA), renforcée en cette période de confinement.
Quelle est le rôle d’un orchestrateur de containers ?
Aujourd’hui les applications ne sont plus monolithiques.
Elles sont au contraire composées de multiples composants mis en conteneurs associés qui doivent fonctionner ensemble.
L’orchestration de containers permet avant tout d’organiser un flux de travail des composants individuels et du niveau des applications.
A partir du processus d’organisation de travail, Les outils d’orchestration de containers permettent aux utilisateurs de guider le déploiement de conteneur et d’automatiser les mises à jour, la surveillance d’état et les procédures de basculement.
Docker et Kubernetes VS Swarm : Évaluation dans le contexte de Cantor
Il y a plusieurs mois, nous avons réalisé une première étude pour évaluer Kubernetes dans notre contexte.
Notre étude nous a démontré qu’il existe bien des alternatives plus adaptés que l’utilisation de Kubernetes. Nous avons donc étudié l’hypothèse d’une orchestration de containers plus pragmatique et simple à intégrer : Swarm.
Pour Cantor, l’orchestration de containers ont des objectifs particuliers :
- Des déploiements et mises à jour simples
- Une meilleure gestion des ressources
- Des services résilients
- Une scalabilité
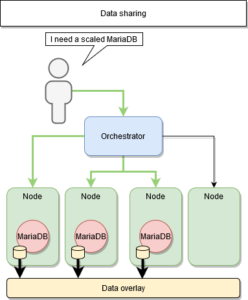
Le contexte d'usage
- Un ensemble de nœuds prêts à l’emploi
- Un (ou plusieurs) manager
- Un (ou plusieurs) worker
- Un moteur de conteneur : Docker
- Un moteur d’orchestration : Swarm
Contexte d’usage d’un container d’orchestration
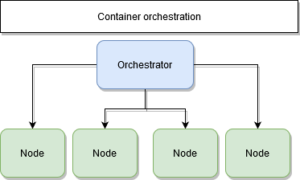
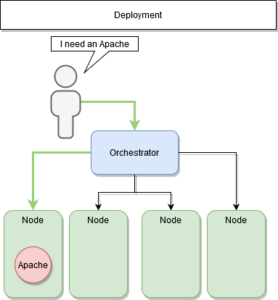
Le (re)déploiement
Dans une architecture orchestrée, nous communiquons uniquement avec nos managers.
Nous leur demandons de déployer nos services, indépendamment de leurs localisations. Le manager définit sur quelle machine le déployer et chaque nœud susceptible de l’héberger.
Déploiement
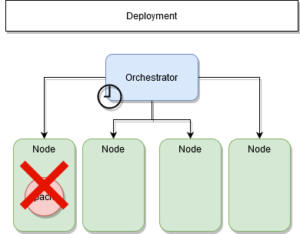
Que se passe-t-il lorsqu’un nœud est hors service ?
Dans achitecture technique comme celle-ci, le rôle des managers est de conserver l’état initial.Cet état initial est définit par les services déployés avec leurs nombres de réplicas. Lorsqu’un nœud est hors service, le manager est averti dans un délai très court.
Il va donc redéployer les services qui étaient présents sur les autres nœuds du système.
ETAPE 1 : Nœud hors service
ETAPE 2 : Redéploiment
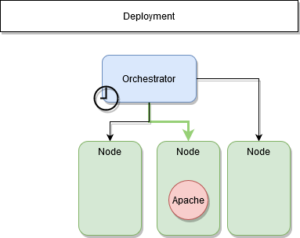
Le service est-il interrompu ?
La scalabilité : déployer plusieurs instances d’un même service
La scalabilité
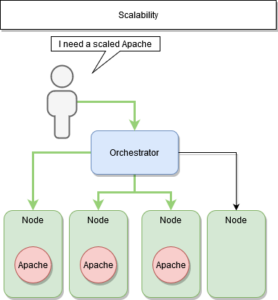
La « scalabilité » est le fait de déployer plusieurs instances d’un même service.
Il y a deux avantages majeurs à la sacalabilité :
- La continuité de service
- La répartition de charge
La continuité de service est assuré par le manager qui conserve son état initial compte-tenu de ses nœuds à disposition.
C’est également lui qui s’occupe de la répartition de charge ou load balancing entre les différents couple nœud-service.
ETAPE 1 : Nœud hors service
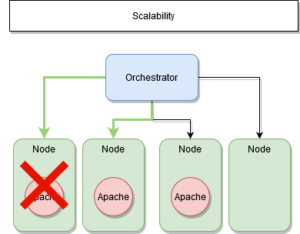
ETAPE 2 : Préserver l’état initial
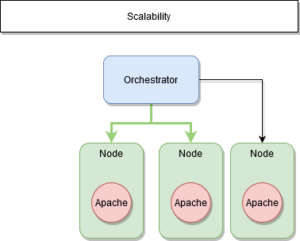
Le manager connaît donc en temps réels les états de ses nœuds et services.
Cela fonctionne parfaitement pour des services « stateless ».
Qu’en est-il des services « stateful » ?
Effectivement, dans ce type d’architecture, le service ou le programme peut être déployé n’importe où sur le système, mais il est indispensable de l’associer aux données qui lui sont propres.
En effet, le programme doit enregistrer les données clients des activités d’une session pour une utilisation dans la session suivante.
ETAPES 3 : Services stateful
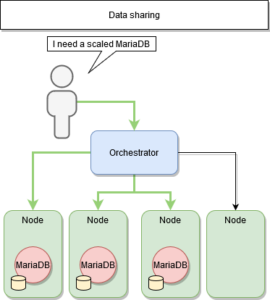
Le partage de données
La solution intuitive est donc de partager les données entre les différents services déployés.
Nativement, Docker propose des volumes pour persister la donnée des conteneurs, cependant Swarm ne gère pas ce partage entre les différents nœuds.
- L’utilisation de services prévus à cet effet
- L’utilisation de solutions externes de mutualisation des volumes
Dans notre premier cas, cela revient à modifier la façon dont sont conçus nos services, dans le cas d’une base de données, Redis est un bon candidat.
Encore faut-il savoir l’intégrer 🙂
Dans notre deuxième cas, il s’agit de plugins Docker.
Ce plugin modifie la façon dont sont gérés les volumes, en étant transverse.
L’idée est d’accéder aux données à travers une API, afin d’obtenir la même source d’information peu importe le nœud.
REX-Ray ou BlockBridge le proposent.
Dans cette deuxième solution, le point d’accès aux données devient à nouveau un maillon faible : S’il est hors service, tous nos nœuds le sont également.
Supposons conserver un cache localement, lequel de nos services possède l’information correcte après plusieurs requêtes de modifications ?
La réponse est intuitive 🙂
Plugin docker
Alors dans quelles mesures peut-on répliquer ce service transverse ?
La question reste ouverte !
Web Assembly
Web Assembly, technologie du Web moderne ?
Qu’est ce que Web Assembly ?
Une extension JavaScript ?
A l’origine, c’est en effet l’effort d’optimisation du JavaScript ASM.js qui est un précurseur de WebAssembly. Cependant, WebAssembly ne se limite pas à de la programmation en JavaScript.
Une nouvelle JVM ?
L’optimisation de JavaScript conduit le groupe derrière WebAssembly à proposer une représentation source proche de l’assembleur. Comme la machine virtuelle Java (JVM) ou Point.Net (CLR), il existe donc bien une représentation intermédiaire, mais contrairement à ces deux cas, l’exécution ne requiert pas l’installation sur le poste client d’un composant exécutant le programme cible. C’est le navigateur qui effectue la traduction, et l’exécution est faite au plus proche du code natif propre au processeur de la machine du client.
Définition du site webassembly.org
Extrait du site webassembly.org :
WebAssembly (abrégé en Wasm) est un format d’instructions binaires pour une machine virtuelle à base de pile. Wasm est conçu comme une cible portable de la compilation de langages [de programmation] de haut niveau comme le C, C++, Rust, facilitant le déploiment sur le Web d’application côté client comme serveur.
Texte anglais d’origine : “WebAssembly (abbreviated Wasm) is a binary instruction format for a stack-based virtual machine. Wasm is designed as a portable target for compilation of high-level languages like C/C++/Rust, enabling deployment on the web for client and server applications.”
Chronologie d’une technologie récente
-
Juin 2015 : annonce de WASM
- Création du WebAssembly Community Group avec des représentants des équipes de développement des navigateurs web :
- Chrome
- Edge
- Firefox
- WebKit
- Création du WebAssembly Community Group avec des représentants des équipes de développement des navigateurs web :
-
Mars 2017 : MVP de l’API WASM (fin des pré-versions expérimentales des navigateurs)
-
Novembre 2017 : support de tous les navigateurs majeurs
-
Mars 2019 : annonce de WASI (WebAssembly en dehors du navigateur)
-
Décembre 2019 : publication de WASM Core 1.0
WebAssembly : Quels objectifs ?
Rapidité
La rapidité est l’un des points clés de WebAssembly :
- Code rapide à télécharger (nécessaire dans un environnement distribué comme le Web)
- Code rapide à l’exécution
Portabilité
Cette technologie orientée pour le Web, donc :
- Doit fonctionner quel que soit le Sytème d’Exploitation cible.
- Doit fonctionner quelle que soit la plateforme matérielle.
Lisibilité
La lisibilité du code doit favoriser la mise au point et les corrections.
Cet objectif reste à réaliser. Dans le fonctionnement actuel, la lisbilité du code repose sur le langage source. Les outils de déverminage (debugging) sont jusqu’à aujourd’hui manquants en termes de maturité.
Sécurité
Dans l’environnement du Web inter-connecté, les questions de sécurité sont tout de suite mises en avant :
- L’exécution ne doit pas diminuer les capacités de fonctionnement du navigateur.
- L’exécution ne doit pas mettre en danger le fonctionnement du Système d’Exploitation hôte.
- L’utilisation systématique d’une mécanique de « bac à sable » s’est donc imposée.
L’étape suivante : WASI
Une des limites de WebAssembly est l’impossibilité d’accéder aux ressources locales du client (notamment les fichiers), du fait de l’exécution dans le navigateur, pour raisons de sécurité.
WASI (WebAssembly System Interface) va permettre de s’affranchir de cette limite, en autorisant l’exécution en dehors du navigateur.
L’importance de WASI (qui reste en développement à l’heure actuelle) est soulignée par la citation suivante de Solomon Hykes, fondateur de Docker, société qui développe le produit très connu du même nom dans le domaine de la conteneurisation d’applications : « Si WASM et WASI avaient existé en 2008, nous n’aurions pas eu besoin de créer Docker ».
Cas d’utilisation de WebAssembly
Dans le navigateur
Quelques domaines d’utilisation de WebAssembly :
- Vision par ordinateur
- Manipulation d’image / de vidéo
- Jeux vidéos
- Réalité virtuelle / augmentée
- Emulation matérielle
- Cryptage
De façon générale, toute application consommatrice de ressource processeur, de calculs intensifs est concernée.
En dehors du navigateur
- Jeux vidéos
- Exécution de code non vérifié côté serveur
- Application côté serveur
- Applications mobiles hybrides (application mobile liée à un ou plusieurs serveurs)
Comment utiliser WebAssembly ?
WebAssembly est une technologie destinée aux développeurs. Cette partie présente de façon illustrée, par un exemple très simple, les principes d’utilisation simplifiée des outils actuels.
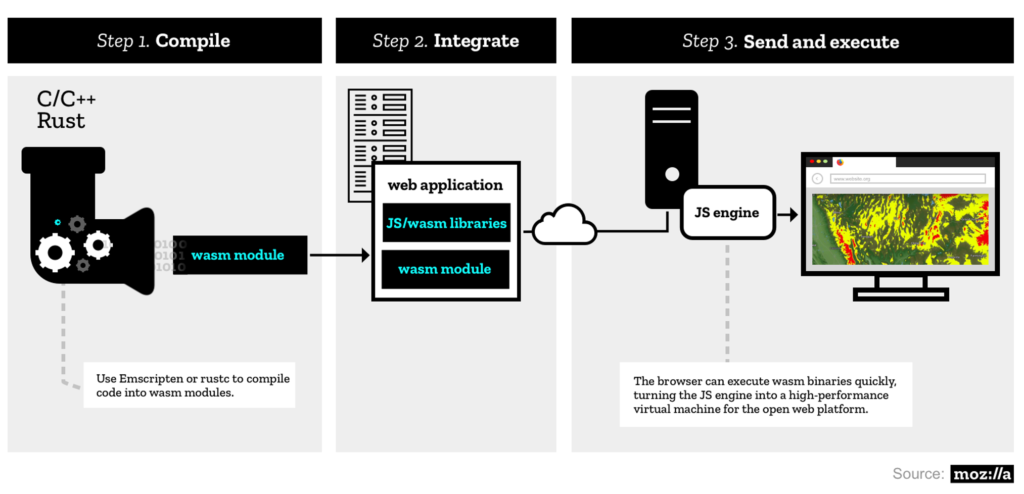
Schéma général
Voici le schéma de fonctionnement général présenté par la fondation Mozilla qui mène le développement du navigateur Firefox :
Les formats source
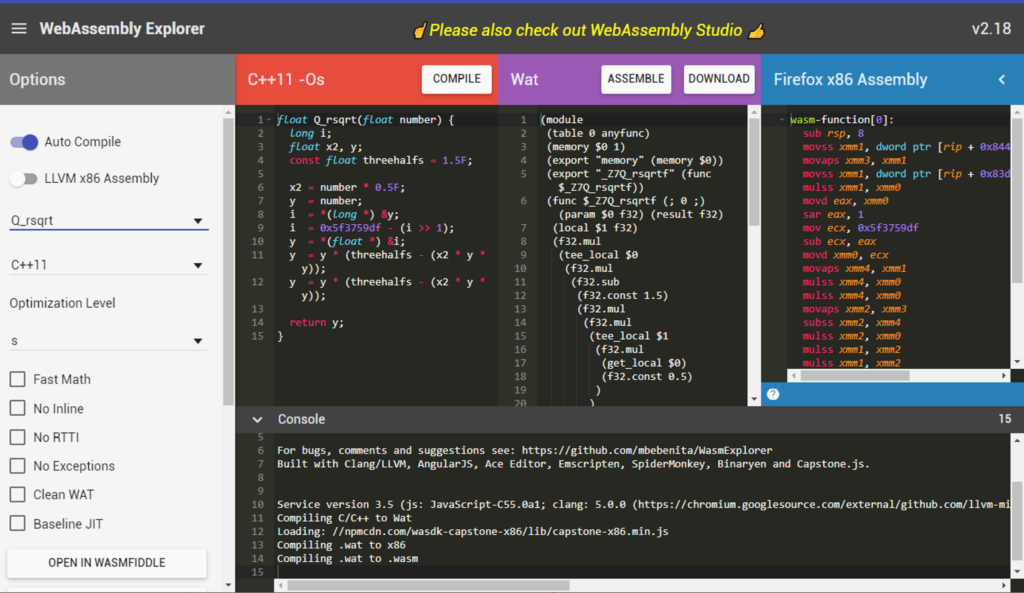
WebAssembly n’a pas été prévu pour être programmé directement, mais plutôt comme du code intermédiaire proche des instructions de base des processeurs. Le programmeur dispose donc du code source dans le langage de haut niveau (C, C++ ou Rust), que le compilateur transforme en un code binaire ou texte Wasm très proche de l’assembleur, et c’est ensuite le navigateur qui traduit en code machine pour le processeur dans son bac à sable WebAssembly.
Voici une comparaison des différentes versions d’un programme écrit en C lors du passage par WebAssembly.
Un exemple simple : Hello Cantor World !
Utilisation de emscripten
Le principal kit de développement en WebAssembly est Emscripten. Il est librement téléchargeable et installable en ligne sur le site et utilisable immédiatement. L’architecture du kit est proche des kits traditionnels de développement en ligne de commande des langages sources supportés (C, C++, Rust).
Hello : le programme en C
L’écriture du code source est faite en langage C. Il s’agit d’une simple ligne d’affichage de la chaîne de caractères « Hello, Cantor World ! », exécuté à l’aide d’une des primitives classiques de la bibliothèque d’entrée-sortie du langage.

Hello : fichier intermédiaire HTML
Le programme se compile exactement de la même manière que pour un programme C habituel, mais les fichiers intermédiaires produits sont différents. On obtient des fichiers javascript, html et finalement wasm. Le code WebAssembly proprement dit est produit dans le fichier wasm, les deux autres fichiers servant d’intermédiaire pour permettre son intégration dans une page web classique, accessible par le navigateur.
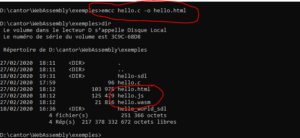
Hello : service du programme
Pour accéder au programme obtenu, un serveur de fichier est nécessaire (il s’agit généralement d’un serveur Web comme Apache ou d’applications javascript comme node.js). En effet, pour des raisons de sécurité, le navigateur ne permet pas l’interprétation d’un fichier de source « inconnue », même disponible localement sur la machine cliente. Le kit de développement facilite le test avec un utilitaire (emrun) inclus pour jouer le rôle de serveur simplifié des fichiers de développement locaux.
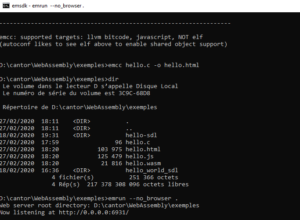
Hello : exécution dans Firefox
Le navigateur internet (Chrome ou Firefox, ou Safari) peut maintenant accéder à l’application et l’exécuter dans son bac à sable de manière transparente, comme s’il la téléchargeait à partir d’un site Web classique.
Hello : fichiers sources WebAssembly
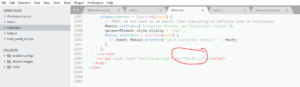
Source HTML
Le fichier source HTML ne sert en fait qu’à encapsuler le logo de emscripten et à inclure le fichier javascript.
Source JS
Le fichier source JS sert à inclure le fichier wasm et à fournir l’interface de chargement du code WebAssembly inclus dans ce dernier fichier.
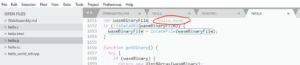
Source binaire Wasm
Le fichier wasm obtenu par la compilation est complètement binaire et ne permet pas un affichage intelligible.
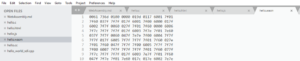
Conversion binaire vers texte Wasm
Il est possible d’obtenir aussi le fichier wasm dans un format texte « intelligible » en convertissant la version binaire. Le kit de développement contient des utilitaires qui permettent de passer d’un format à l’autre.

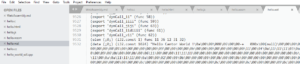
Source du binaire Wasm en texte
Le fichier wasm obtenu par conversion est affichable en texte, comme du code source habituel. Cependant, les instructions restent très proches de l’assembleur des processeurs, et donc moins compréhensible que le code source C d’origine.
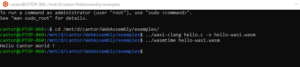
Hello : exécution avec WASI
Le kit de développement WASI est encore en phase préliminaire et n’est pas disponible directement pour Windows. On peut cependant l’utiliser sous Windows avec la couche Windows Services pour Linux, dans un Linux hébergé de cette façon. Le kit est librement téléchargeable et installable.
Voici l’exécution de notre programme avec l’exécuteur en temps réel de WASI, wasmtime.
Exemples d’applications actuelles
WebAssembly n’est pas qu’un format pour développeur à la pointe du progrès. Il existe déjà des applications distribuées de cette manière par des éditeurs logiciels de premier plan.
- AutoCAD : https://web.autocad.com
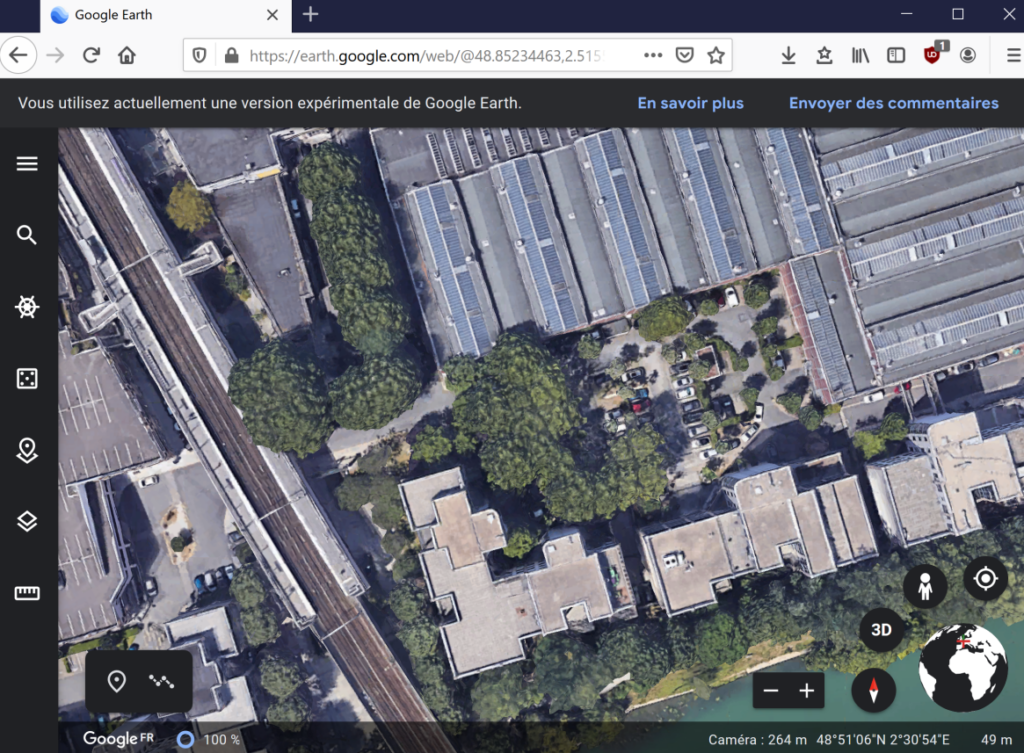
- Google Earth Web : https://earth.google.com/web/
Voici les bureaux de Cantor visibles dans la version Web de GoogleEarth, distribuée notamment en WebAssembly :
Conclusion
WebAssemly est une technologie à suivre, par ses capacités de migrer des applications d’envergure vers un format très adapté au déploiement sur le Web. Nul doute qu’elle va se répandre de façon considérable dans le monde applicatif distribué.

Design For Failure ou Comment rendre une application résiliente aux pannes ?
Design For Failure : Comment rendre une application résiliente aux pannes ?
Le Design For Failure (DFF) est la capacité d’un système à résister aux pannes d’autres composants, autrement dit la résilience d’une application.
- Tolérance aux pannes
- Prévention des pannes
- Supervision
Même si on a conçu un système très résilient qui arrive à se réparer tout seul, il est important de savoir s’il s’est passé quelque chose.
Illusions de l’informatique distribuée
| Le réseau est fiable | Le temps de latence est nul | La bande passante est infinie | Le réseau est sûr |
| La topologie du réseau ne change pas | Il y a et un seul administrateur réseau | Le coût de transport est nul | Le réseau est homogène |
Comment fonctionne le Design for failure ?
La loi de Murphy nous dit : tout ce qui est susceptible d’aller mal, ira mal !
Il faut donc se préparer aux erreurs des différents éléments qui composent notre application.
Dans un premier temps, essayer de réparer les erreurs
puis donner une réponse dégradée si besoin
Et ne pas oublier d’informer l’utilisateur.
Les principaux patterns
DFF Côté client
Timeout

Principe bien connu, c’est un de premiers paramètres pour toutes communications distantes (Call HTTP, Read I/O…) : c’est la définition d’un temps d’attente maximal.
Sa durée est à bien définir en fonction du SLA du service interrogé : sur un service d’autocomplétion il doit être ultra-court, mais sur un appel à une base de donnée, il pourra être plus long.
Attention à ne pas oublier de le parametrer car sa valeur par défaut peut nous surprendre :
- en C# le timeout HttpClient par défaut est à 100 secondes ! (docs.microsoft.com)
- en Java / OkHttp, le timeout par défaut est à 0, c’est à dire qu’il attendra indéfiniment (okhttp3)
Retry

Souvent mis en place par défaut dans les applications réseaux (FTP, Message Queues…), il permet de combler à une micro-coupure du réseau.
Bien définir la durée d’attente entre chaque essai et leur nombre
risque de DDos si plusieurs clients se mettent à réessayer continuellement d’appeler un service à l’agonie. Idéalement le délai d’attente sera exponentiel.
Bien définir les causes qui génèrent un nouvel essai
pas de retry pour une erreur de mot de passe !
Attention si la requête n’est pas idempotente
risque de corruption de données
Fallback

Le Plan B : on répond quoi qu’il arrive, soit une réponse normale, soit une réponse dégradée.
Ce qui nous permet d’éviter les erreurs génériques aux utilisateurs.
La réponse dégradée doit être définie avec le métier (message d’erreur contextualisé), il faut informer l’utilisateur qu’il est en mode dégradé.
Notamment pour éviter de mettre en cache une réponse dégradée !
Le Fallback doit être rapide et fiable, prenons l’exemple la résolution DNS d’une URL :
- le cache du navigateur
- le proxy dns du réseau local
- le proxy dns du FAI
- les serveurs racines de l’ICANN
Circuit Breaker

On arrête de s’acharner sur un service qui ne répond pas.
Sur le même principe qu’un disjoncteur électrique, on coupe le circuit,
mais en fonction de règles définies, on va chercher à re-tester périodiquement
la cible pour rétablir le circuit de façon automatique.
Un disjoncteur a 3 états (en informatique au moins) :
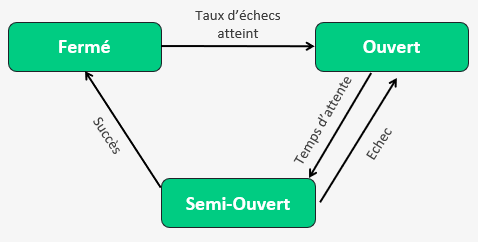
Fermé : tout va bien
les requêtes passent toutes vers leur destination, on alimente l’état de santé du circuit,
jusqu’à ce qu’on atteigne le taux d’échecs et on ouvre le circuit
Ouvert : rien ne vas plus
Toutes les requêtes sont bloquées, on laisse le système cible respirer un peu (il est en PLS), puis une fois le délai d’attente dépassé on passe à l’état suivant
Semi-Ouvert : peut-être que…
On entrouvre le circuit et laissons passer quelques requêtes pour voir comment se comporte le système cible (les ambulanciers sont-ils arrivés ?).
S’il y a toujours des erreurs on repasse à l’état ‘Ouvert’,
mais si les requêtes passent correctement on passe à l’état ‘Fermé’ pour rouvrir les vannes.
Le passage d’un état à l’autre peut-être déclenché de plusieurs façons :
- Nombre d’erreurs / succès basé sur un code de retour
- Nombre d’erreurs / succès basé sur un temps de réponse
- Pourcentage d’erreurs sur une période donnée
- Métrique sur une ressource (% CPU d’une VM)
- Déclenchement manuel (Mise à jour d’une dépendance ?)
=> La supervision est *primordiale* !
Rien de plus frustrant que de déboguer une application pour comprendre pourquoi un service ne répond pas alors que le circuit est ouvert…
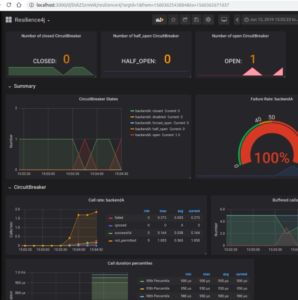
Voici un exemple de monitoring avec Resilience4J
Bulkhead

L’idée c’est d’éviter les effets dominos : une trou dans la coque ne doit pas faire couler le bateau
On parle ici d’isolation de processus à différents niveaux :
- CPU / Thread Pool (Polly / Hystrix / Resilience4J…)
- CPU / Mémoire (WebServer App Pool / Docker…)
- Hôte (VMWare, Kubernetes Pods…)
- Ressources physiques (Cluster, DataCenter, Cloud…)
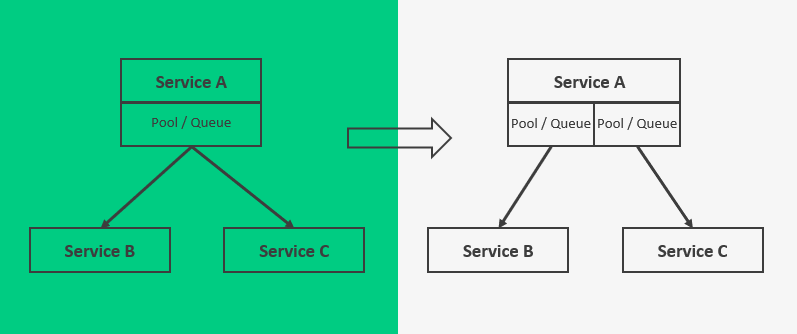
Dans le schéma ci-contre, si le service B vient à ralentir voire ne plus accepter de requêtes, on peut isoler les processus d’envoi pour ne pas pénaliser les requêtes au service C.
BackPressure & Rate Limiter
L’empathie entre services

Il s’agit ici de limiter les appels à une ressource, et même de garder un visu sur la santé de cette ressource.
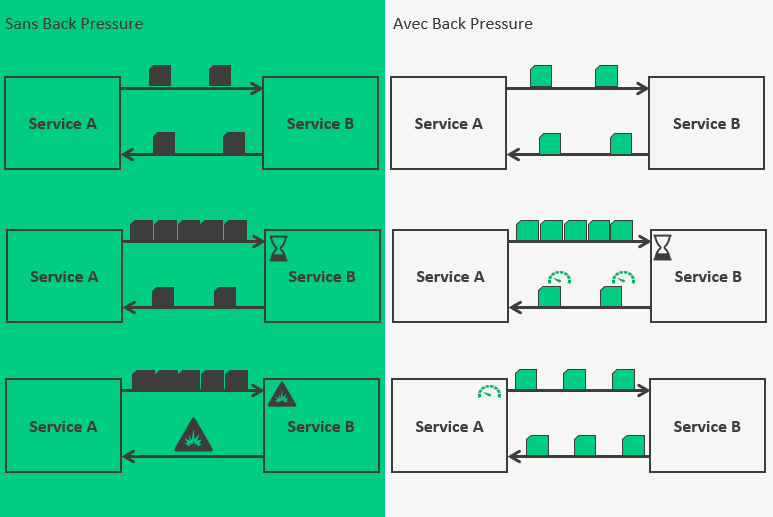
Sans BackPressure, lorsqu’il y a peu d’appels, tout va bien,
mais lorsque la charge augmente, et que le service cible n’arrive pas à dépiler sa pile de requête assez rapidement, il va surcharger, puis il risque de partir en erreur.
Avec BackPressure, la réponse du service cible est contenue dans une enveloppe qui décrit la santé du service. Si la charge devient trop élevée, le service cible pourra signaler un ralentissement dans son traitement, et le service demandeur devra limiter ses requêtes (le rate limiter).
Les Frameworks
Java
Hystrix (NetFlix)
Premier framework de résilience (en Java), rendu open-source, mais ensuite délaissé (fin 2018) par NetFlix
https://github.com/Netflix/Hystrix

Resilience4J
Librairie Java inspirée d’Hystrix, mais implémentée en suivant les préceptes de la programmation fonctionnelle.
https://github.com/resilience4j/resilience4j
Javascript
HystrixJS
Portage d’Hystrix en Javascript
https://www.npmjs.com/package/hystrixjs
Simplified-hystrixjs
https://github.com/julekgwa/simplified-hystrixjs
Brakes
.NET
Hystrix.NET
Portage d’Hystrix en .NET
https://github.com/Travix-International/Hystrix.Dotnet
Polly
Librairie inspirée d’Hystrix, mais dotnet native
http://www.thepollyproject.org/
et accessoirement mise en avant par Microsoft (docs.microsoft.com)
API Gateway & Service Mesh
DFF Côté service
Jusqu’à maintenant on a parlé de comment protéger des appels vers des services externes. Il faudrait donc répéter/réutiliser/dupliquer les stratégies de DFF pour chaque services distants, comme dans le schéma suivant :
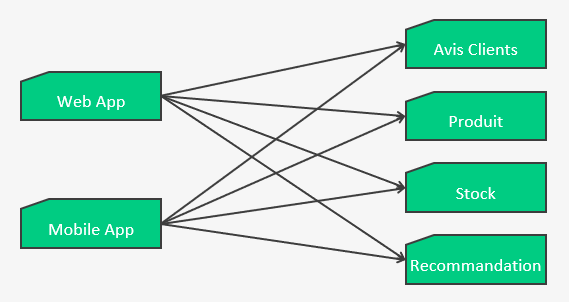
C’est là qu’interviennent les principes d’API Gateway, de BackForFront et de Service Mesh
API Gateway
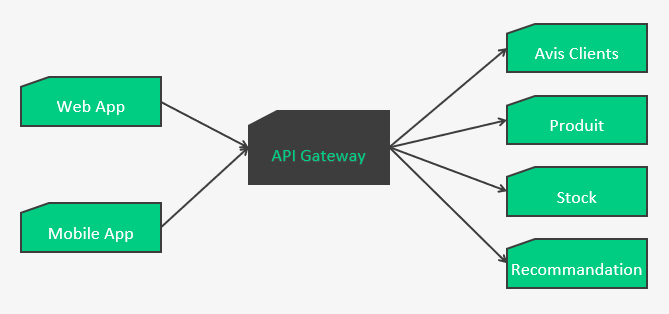
L’API Gateway va servir de proxy et centralisation pour protéger les services distants.
Et là vous me rétorquerez qu’on a juste déplacé le problème ! Oui et non, car maintenant on peut s’appuyer sur d’autres plateformes pour gérer l’API Gateway. Cette brique n’as pas besoin d’être développée et maintenue en interne, on peut utiliser celles qui sont sur le marché et ainsi ne gérer que de la configuration, telles que (liste non exhaustive) :
De plus, ça va limiter les échanges réseaux entre les apps et les services distants. D’un côté ça augmente la sécurité (les services distants n’ont plus à être visible depuis internet, et en terme de flux réseaux on sait exactement lesquels doivent rester ouverts et être sécurisés), de l’autre ça réduit la quantité de données transitant entre l’application et les services distants (merci les forfaits Data des téléphones).
Back For Front
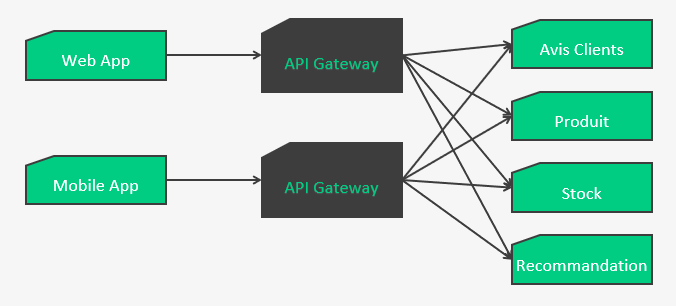
Les BestFriendForever BFF sont une variante de l’API Gateway, où une gateway va se spécialiser et se dédier à une application front.
Service Mesh
Et maintenant comment ça se passe dans une galaxie de microservices ?
Dans le cas où un service doit en appeler d’autres ?
Potentiellement on peut arriver sur ce genre de résultat :
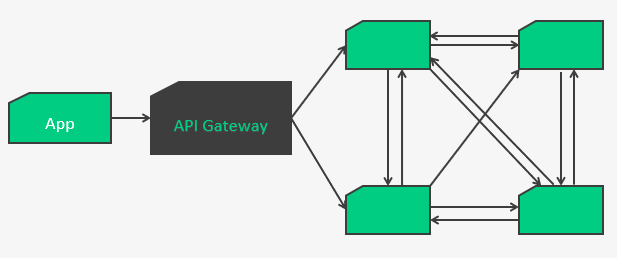
La complexité de gestion d’incident, de discovery, de load-balancing grimpe de façon exponentielle et quid des mises à jour ? Autant de code de gestion technique qui vient polluer le code métier.
C’est là qu’interviennent les service meshs avec le pattern de sidecar proxy.
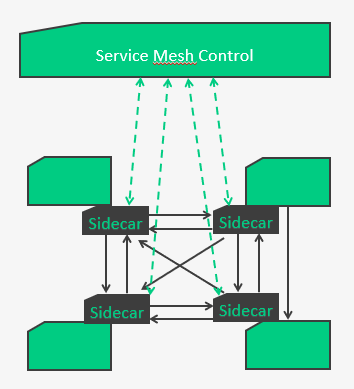
Les services ont tous un sidecar proxy associé par lequel passeront toutes les communications réseaux. C’est donc eux qui viendront s’identifier sur le control, qui s’occuperont de toute la remontée de stats (pour l’état des disjoncteur par ex), qui géreront toute la complexité des échanges services à services.
A partir du control, on pourra avoir un suivi en temps réel des communications,
gérer les flux (rate limiter par ex)…
Voici une liste non-exhaustive des solutions de service mesh sur le marché
En quelques mots un service mesh permet de :
- simplifier l’interconnexion des services
- sécuriser les services (autorisation, identification, chiffrement des échanges)
- contrôler les flux
- surveiller l’état des communications
Pour conclure
Comme tous les patterns, ceux présentés ici sont à utiliser à bon escient,
et avec le bon framework leur mise en place peut-être facile.
Il faut toujours valider avec le métier les paramètres du DFF et le mode dégradé.
Il ne faut surtout pas sous-estimer :
- Les tests et tuning des paramètres
- La supervision
Pour aller plus loin :
- Design For Failure au niveau Infra (Autoscaling Group…)
- Chaos Engineering : http://principlesofchaos.org
Principe né chez Netflix, l’idée c’est de tester en PROD la perte d’une application/serveur/datacenter, et ils ont donc développé tout un tas d’outils qui viennent perturber leur environnement de production : Chaos Monkey (qui détruit des VMs) et toute la suite Simian Army
Références
La résilience chez Netflix
https://netflixtechblog.com/making-the-netflix-api-more-resilient-a8ec62159c2d
Resilience4J Graphana dashboard
https://dev.to/silviobuss/resilience-for-java-microservices-circuit-breaker-with-resilience4j-5c81
Le chaos engineering à la SNCF
https://www.lemagit.fr/actualites/450430813/Chaos-Engineering-ou-le-stress-ultime-des-applications-et-de-linfrastructure-et-utilise-par-OUISN
https://ouitalk.oui.sncf/article/focus/tout-en-ordre-lingenierie-du-chaos-chez-ouisncf
L’excellent article d’Objectif Libre
https://www.objectif-libre.com/fr/blog/2019/09/05/service-mesh-decouverte-et-mise-en-oeuvre
Service Mesh Guide
https://www.infoq.com/articles/service-mesh-ultimate-guide
Merci à Antonio Gomes Rodrigues

Suivi de température d'une salle serveurs
Comment suivre la température
d'une salle serveur ?
Dans quel contexte suivre la température d’une salle serveur ?
Après un problème de clim survenu malencontreusement dans la salle serveurs, nous avons compris l’urgence d’installer un système permettant de mesurer et de gérer la température de la salle de façon constante. Un système qui permet d’être averti en cas de clim en panne !
À Cantor, nous avons un pôle informatique industriel et instrumentation … alors nous pouvions le faire nous-même, rapidement et pour un coût négligeable.
Le Raspberry Pi est un nano-ordinateur avec un processeur ARM. En plus de sa petite taille, de son faible coût, la consommation de celui-ci est assez faible et il convient pour la surveillance à distance (dans un environnement non industriel). Ce système nous permettrait donc de surveiller à distance et de façon constante la température et surtout d’être averti en quelques minutes si la clim du local technique tombe en panne.
Ainsi pour mesurer la température de notre salle serveurs nous nous sommes doté d’un Raspberry Pi et d’une sonde 1-wire DS18B20.
Quel matériel nécessaire ?
– un Raspberry Pi 2
– Une sonde de température DS18B20 1-wire (entre 1 à 6 € selon le modèle)
– Une résistance de 4.7K Ω
– Quelques câbles
Soit un budget total d’environ 50 €.
Quel montage ?
Nous avons fait le choix pour notre montage d’opter pour des sondes DS18B20 qui utilisent le bus 1-wire. La résolution de celle-ci est ajustable, soit de 9 à 12 bits et la plage de mesure est de -55°C à 125°C. Le bus 1-wire est basé sur la notion de maître/esclave. Le maître, ici le Raspberry Pi, interroge les différents esclaves à travers le bus ou leur envoi des ordres. Il est donc possible de brancher plusieurs sondes en parallèle sur notre bus.
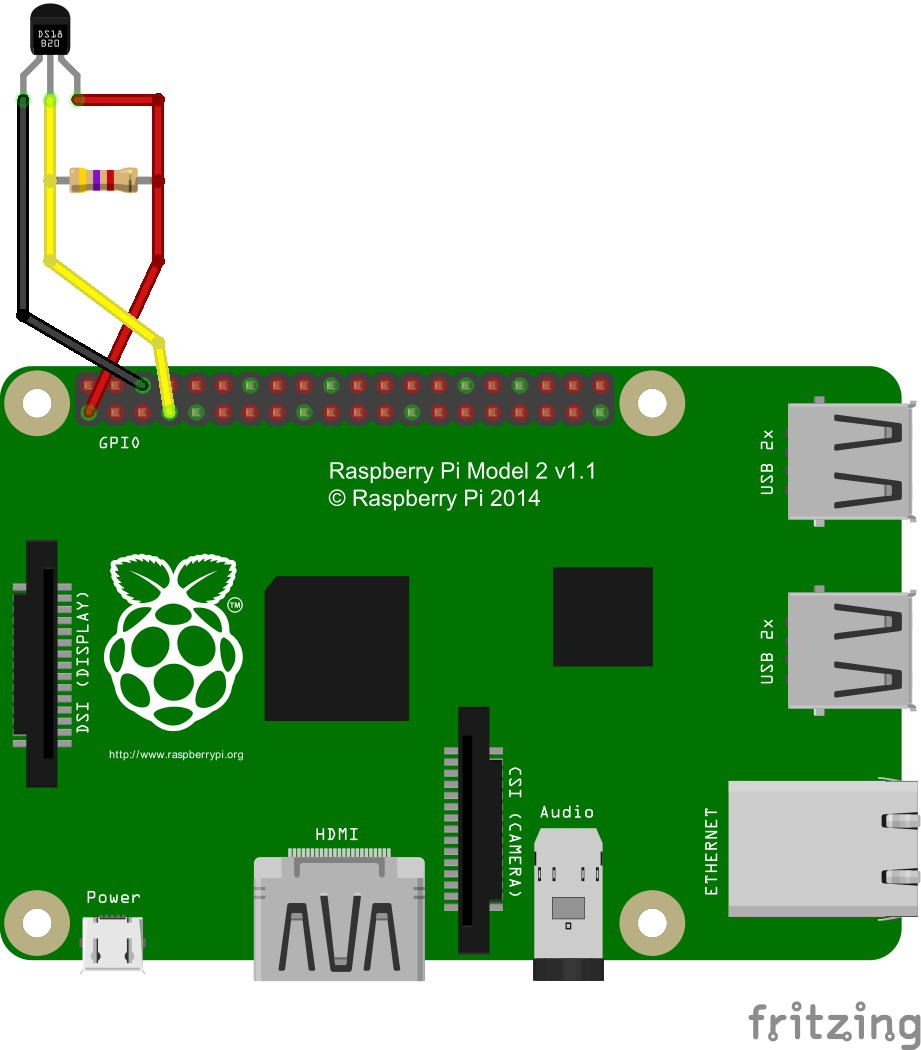
Schéma branchement sonde DS18B20
Ainsi nous avons donc branché l’alimentation du capteur sur la pin 3.3V du Raspberry Pi, la masse du capteur sur la pin de masse et enfin la patte de données de la sonde à la pin GPIO 4. La résistance de 4.7K Ω est alors placée entre l’alimentation et le fil de données. Afin d’éviter toute surchauffe nous avons pris le soin de vérifier le sens de branchement de la sonde.
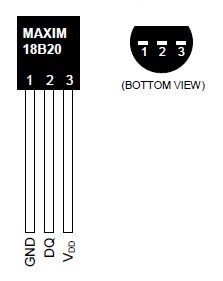
Sonde DS18B20
Quelles résultats ?
Après avoir configuré le système et programmé la surveillance, nous avons en permanence l’enregistrement des températures et accès à l’historique (tiens, quelqu’un a ouvert la porte 🙂 )
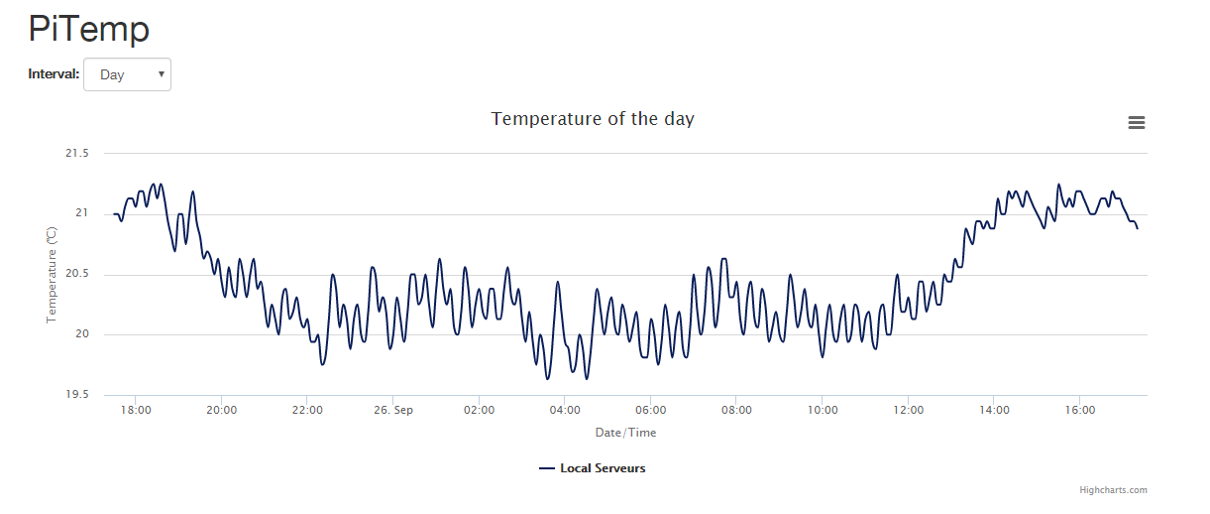
L’envoi d’un email d’alerte à notre équipe infra reste le point clé du projet. Dès que la température dépasse le seuil que nous avons configuré, un mail est envoyé à l’équipe infra, qui pourra intervenir au plus vite.

Quel bilan ?
Notre solution « surveillance de la température d’un local technique » fonctionne 24 heures sur 24, 7 jours sur 7 et 365 jours par an. Avec une technologie simple et un coût négligeable.
N’hésitez pas à nous contacter si vous souhaitez des détails sur cette petite installation.

Analyse de particules - Première partie
#1 Analyse de particules
Comment analyser les images ?
Dans le domaine de l’analyse d’images, un problème récurrent est celui de la détermination des caractéristiques morphologiques individuelles de particules dans un ensemble plus vaste.
Les domaines d’application sont très variés. On citera par exemple en biologie les fréquences de particules d’ADN anormales dans une série d’images obtenues par microscopie optique. Autre exemple, les calculs de diamètres de particules en suspension dans les huiles dans l’extraction du pétrole, ou encore les répartitions de tailles de grains de composés étudiés dans la métallurgie.
Le but est souvent de permettre l’automatisation des calculs sur des séries d’images, particulièrement quand les particules à étudier sont nombreuses.

Quel contexte pour l'analyse de particules ?
L’idée centrale de l’analyse individuelle de particules est de calculer de façon simultanée, ou en tout cas d’effectuer en un nombre minimal et maitrisé de balayages sur chaque image, une batterie de mesures individualisées par particule.
Après détermination, des caractéristiques telles que la taille, la morphologie et la composition des particules sont analysées afin de les classer, les filtrer et finalement en extraire l’information recherchée.
Quel sont les grands principes ?
- Individualisation des particules
La première étape est de traiter l’image afin d’obtenir une image binaire (souvent de façon automatisée) puis d’individualiser les objets obtenus après binarisation, ce qui revient à les compter.

- Calcul des mesures individuelles
Une première phase de calcul des mesures des particules s’effectue en un minimum de balayages sur chaque image. Il s’agit de mesures primaires (par exemple, l’aire et le périmètre bruts de chaque particule).
Dans une deuxième phase, les mesures composées, c’est-à-dire combinant plusieurs mesures primaires, sont déduites particule par particule.
Ces deux phases sont naturellement essentielles dans l’analyse de particules.
- Filtrage des particules
A partir des mesures calculées, il est possible alors de filtrer les particules en suivant des règles déterminées par les utilisateurs. Les règles les plus simples sont de respecter des seuils de variation pour une ou plusieurs mesures choisies. Elles servent ainsi à éliminer les particules anomales dans la population étudiée.
Comment présenter les fonctionnalités et les principes de conception ?
La fréquence et les similitudes dans la résolution de ce type de problème nous ont amenés à fourbir une boîte à outils de transformations d’images relativement classiques, dont la première qui est la numérotation de la population de particules que l’on veut étudier. La partie centrale de la boîte à outils est l’implémentation du calcul des mesures prises, ainsi que la façon de les archiver dans une base de données. Il s’agit de pouvoir retrouver aisément toutes les mesures qui ont été prises et calculées pour chaque particule, tout en autorisant inversement, pour chaque mesure calculée, d’en obtenir l’histogramme pour toutes les particules.

Un cas qui revient souvent est celui du classement de la taille des grains dans des matériaux. Le calcul d’une mesure particulière (typiquement la surface) est choisi sur ce qui est visible dans l’image. Le calcul est itéré sur toutes les particules individualisées, représentant par exemple des graviers, et est suivi d’un filtrage par taille. L’équivalent est une opération de tamisage numérique pour obtenir une répartition granulométrique.
Pour réaliser ce genre d’opérations, nous avons mis au point une bibliothèque de traitement dans laquelle on calcule toutes les mesures qui sont sélectionnées. Ce module, nommé Escalus, opère les calculs et gère les résultats de mesure en permettant de les ranger soit pour une particule donnée, soit pour une mesure donnée et cela de façon simultanée.

Pour implémenter la manipulation des images nous utilisons une deuxième bibliothèque maison, soit Noema, qui permet de gérer les données images (pour y accéder et y écrire) et dans laquelle on a également la notion de transformation qui permet de traiter un ensemble d’images en parallèle. Nous pouvons ainsi obtenir l’image binaire avec une mécanique de parallélisation des traitements en pipeline. Ce module favorise de façon générale la parallélisation du traitement dès qu’on affine une image à l’entrée du pipeline (ou plusieurs images en fonction du nombre de tuyaux), la capacité du système dépendant bien sûr du nombre de machines disponibles. De fait, les traitements sont effectués en cadence comme sur une chaîne de production. Ce système permet d’exploiter les capacités parallèles des processeurs.

Docker & Ansible
Comment mettre en place un système centralisé de logs avec Docker et Ansible ?
Aujourd’hui, nous utilisons de nombreuses applications dans des buts très divers. De ce fait beaucoup d’échanges sont effectués entre les utilisateurs et les applications et même entre applications. Ce qui a pour effet de générer un nombre conséquent de logs. Ainsi avec la multiplication de ces échanges, les utilisateurs ne peuvent pas consulter manuellement toutes les applications pour consolider ces données.
L’idée était donc de mettre en place un système qui permettrait de simplifier ce processus de consultation pour toutes nos applications.
Ainsi à Cantor, étant donné que 90% de notre infrastructure est « dockerisée », nous avons décidé d’en profiter pour mettre en place un système centralisé afin d’optimiser notre temps de travail en réduisant les efforts nécessaires à la consultation fastidieuse des fichiers logs.
Pourquoi une simplification des fichiers logs ?
Ayant pour fonction le stockage des lignes d’informations générées par le serveur, la gestion des fichiers de logs est bien souvent contraignante, cependant il s’agit d’une source d’information précieuse, permettant la détection d’erreurs.
L’objectif était donc de ne plus aller consulter manuellement les fichiers journaux, ce qui impliquait de se connecter sur chaque machine, d’obtenir le lieu de stockage des fichiers logs de chaque application avant de pouvoir les consulter.
Pour simplifier cette gestion des logs, nous avons donc cherché à mettre en place un système centralisé et basé sur notre utilisation de Docker.
Quel système centralisé par Docker ?
Pour consolider les logs de toute une infrastructure dans une seule et unique application, Cantor a choisi d’intégrer une stack ELK avec Docker. Soit l’acronyme de trois projets open source : Elasticsearch, Logstash et Kibana.
En effet les composants ELK sont libres et gratuits, sans compter leur configuration simple et le fait qu’il n’y a pas d’impact applicatif. La mise à disposition de leur conteneur s’est intégrée parfaitement avec nos pratiques et nous avons de cette façon pu facilement mettre en place l’environnement.
De façon plus détaillée, la stack ELK se trouve en bout de chaîne d’une centralisation à deux niveaux. Dans un premier temps, les méthodes de logging natives à Docker nous permettent de centraliser les logs sur un seul et même conteneur dans un voisinage réseau. C’est à ce stade que le deuxième niveau prend place, avec une synchronisation distante des logs auprès de chacun des conteneurs de premier niveau. Nous sommes alors capables d’obtenir l’intégralité de nos fichiers de logs de cette façon, qui sont ensuite indexés dans la stack ELK.
Un des avantages implicites de cette centralisation est l’économie d’espace disque. D’une part les logs ne sont plus stockés localement sur nos applications, et d’autre part la stack ELK possède un système de purge permettant de fixer nos règles de conservation des logs.
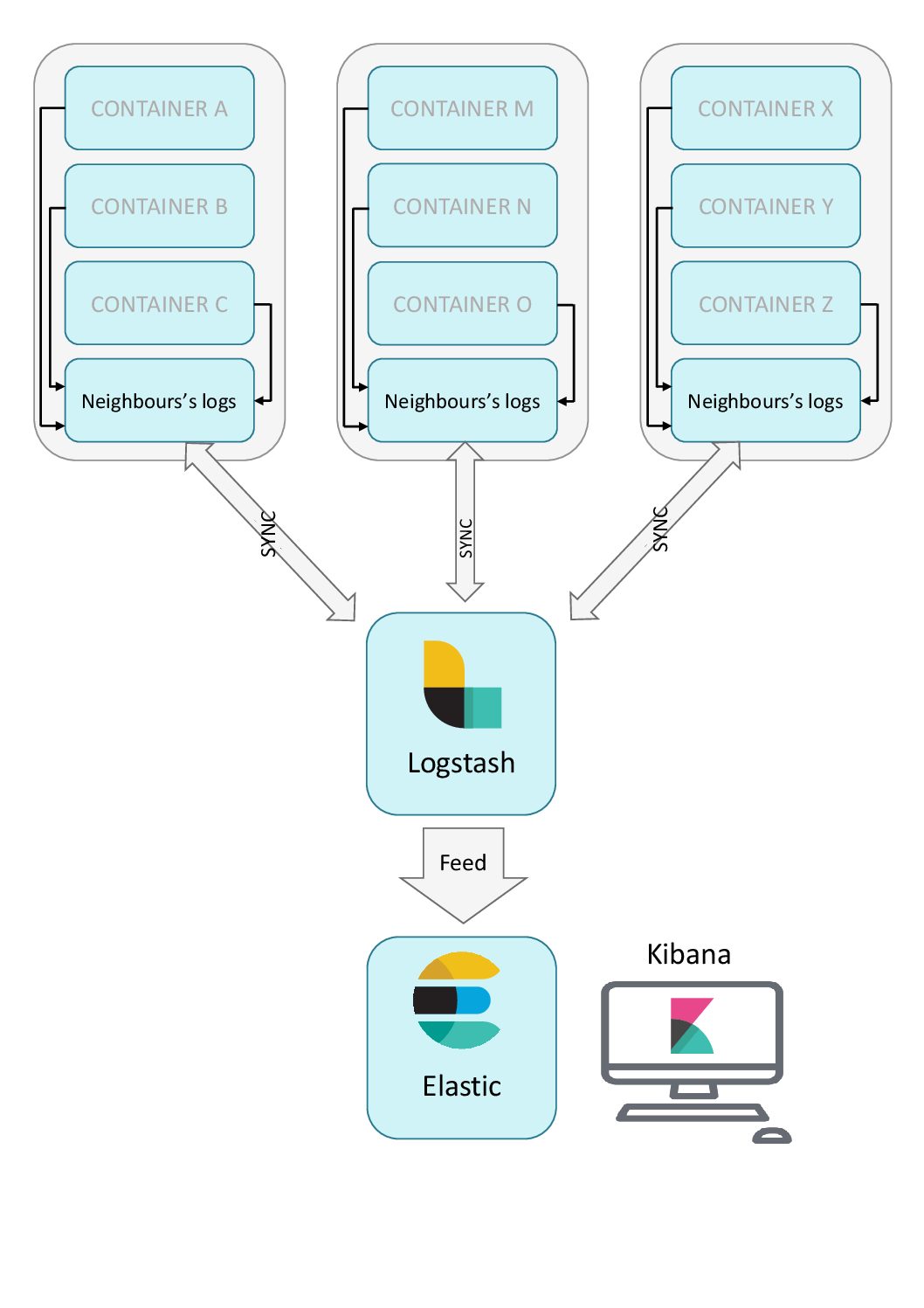
Quelle système d’automatisation avec Ansible ?
L’automatisation est aujourd’hui un élément essentiel de la transformation numérique.
En complément de Docker, nous utilisons donc Ansible pour orchestrer nos déploiements de conteneurs ou de configurations. Ce qui nous permet de configurer automatiquement nos machines pour les brancher sur notre chaîne de log.
Ainsi nous avons la capacité de déployer l’ensemble des containers de gestion de logs en une ligne de commande, que ce soit pour les containers locaux à chaque VM ou pour le cœur de la stack ELK mais aussi pour l’outillage en charge de rapatrier l’ensemble des logs de chaque VM.
L’automatisation avec Ansible a permis un gain de temps considérable et surtout d’éliminer les taches répétitives.
En somme, chez Cantor nous sommes capables de nous abstraire de la gestion des fichiers logs en mettant en place un système de centralisation à deux niveaux. A l’aide de Docker et Ansible, la totalité de notre infrastructure est concernée et branchée sur notre chaîne de logs et nous pouvons à tout moment les consulter au travers de tableaux de bords sur une seule et même interface de visualisation.
Cordova VS React Native : deux frameworks plein de possibilités
Cordova VS React Native : deux frameworks plein de possibilités
Depuis quelques années, Cantor s’intéresse de près au développement mobile.
Lors d’une mise en oeuvre d’application mobile chez un de nos clients, nous avons été confrontés au choix du framework. Nous avons donc comparé deux outils : Cordova et React Native.
Les Frameworks : React Native & Cordova
Ces deux outils sont des frameworks de développement mobile hybrides : ils permettent de développer sur un unique outil une solution qui se déclinera ensuite en application mobile sur toutes les plateformes (Android, iOS…).
L’objectif est évidemment d’optimiser la charge de travail et/ou avoir une application multi-plateformes sans en payer le coût.
Notre analyse
Si Cordova est installé depuis 2011 dans le milieu des frameworks hybrides, React Native fait office de petit nouveau, ayant été lancé en 2015 par Facebook. Et comme toute nouveauté, ce framework attire la curiosité. Cependant, vaut-il la peine qu’on laisse Cordova dans un coin ? Cela dépend de vos objectifs et du timing.
React Native offre plus de fonctionnalités et de modules pour le développement mobile, mais il est plus difficile à mettre en place que Cordova. Plus complexe au niveau structurel, il demande également quelques adaptations en fin de parcours selon si l’on développe pour iOS ou Android. La courbe d’apprentissage pour React Native est plus longue que pour Cordova.
Cependant, les avantages ne sont pas moindres : avec une bonne gestion des ressources des terminaux, React Native peut être plus rapide et puissant que son aîné. Son approche plus « native » du développement permet de se reposer sur des composants du mobile, alors que Cordova utilise des WebViews. En bref, les capacités de l’outil font qu’il est facile de se laisser tenter !
Après cette rapide comparaison, nous avons décidé de passer par le chemin le plus long et de former nos ingénieurs à React Native.
Pour aller plus loin : https://initech.co.il/en/blog/2016/09/19/react-native-vs-cordova-comparison/ et https://www.toptal.com/mobile/comparing-react-native-to-cordova (articles en anglais)

Partenariat d’excellence de Stibo Systems avec J2S et Cantor
Partenariat d’excellence de Stibo Systems avec J2S et Cantor
Stibo Systems développe un partenariat d’excellence avec J2S et Cantor pour accompagner ses clients sur les problématiques Print du MDM
Stibo Systems, spécialiste de la gestion des données de référence multi-domaines (MDM), vient d’initier un partenariat avec J2S – expert des systèmes de publication – et Cantor – société de services et d’ingénierie informatique. Ce partenariat a pour but de mieux accompagner les clients utilisateurs de la plateforme MDM de Stibo Systems – appelée STEP – dans leurs problématiques liées à la gestion du print et notamment à l’édition de catalogues.
Le print, notamment au travers du catalogue, reste un canal stratégique ayant un impact direct sur le CA et sur le branding pour de nombreux vendeurs – y compris en cross canal. L’utilisation d’une plateforme MDM (Master Data Management) permet d’optimiser les processus de publication des données marketing.
C’est ce constat qui a poussé Stibo Systems à se rapprocher de J2S et Cantor. Ce partenariat permet aux trois acteurs de réunir leurs expertises et de proposer aux entreprises un meilleur accompagnement autour de la plateforme STEP et de son module Print.
Stibo Systems, J2S et Cantor entretiennent une histoire commune forte, qui a commencé il y a plusieurs années, avec un projet européen d’harmonisation de la production du catalogue Manutan – soit 2 500 pages déclinées en 12 versions pour une diffusion à l’échelle européenne. Ils sont intervenus, plus récemment, chez un autre acteur important du marché français pour optimiser la chaîne de production de leur catalogue principal.
La plateforme STEP de Stibo Systems apporte plusieurs bénéfices aux entreprises. Les utilisateurs disposent – grâce à elle – de données cohérentes et complètes permettant d’offrir une synergie des supports et des informations précises sur les produits, les prestataires, ou encore les clients tout en réduisant le temps passé à entrer manuellement les données via l’importation de sources externes et la possibilité de manager l’information quelles que soient leurs langues.
En tant que partenaire de Stibo Systems, J2S a pour rôle d’aider les clients à maîtriser la chaîne de production print complète tandis que Cantor assure la stabilité du modèle de données de façon à exploiter au mieux les informations marketing, à optimiser les processus et à accompagner le changement.
Les projets print ont un impact majeur sur l’organisation des entreprises. Ils adressent la façon dont les données marketing sont traitées et exploitées mais aussi l’intégration des systèmes, la sécurité et les processus de travail entre collaborateurs internes et externes.
« J2S est particulièrement fier de pouvoir former avec Stibo Systems et Cantor une équipe complémentaire au service des projets MDM des acteurs français. Le savoir-faire de J2S dans la mise en place des chaînes de production print complètes permet aux utilisateurs de STEP d’industrialiser avec succès et de bénéficier d’une expérience fluide dans leurs processus print. » explique Richard Loubéjac, Cofondateur de J2S.
Philippe Finkel, président de Cantor, ajoute : « Nous sommes partenaires de longue date avec Stibo pour délivrer à nos clients une architecture simple, saine et solide du Data Model et de ses interfaces. Le partenariat avec J2S nous permet de couvrir toute la chaine des catalogues et du Print autour de STEP pour garantir la cohérence et l’intégrité de la donnée multi-canal »
« Accompagner au mieux les clients sur le print était pour nous un enjeu primordial. J2S et Cantor disposent d’expertises totalement complémentaires dans le cadre de la gestion du print c’est pourquoi nous avons décidé de nous rapprocher de ces deux partenaires de longue date pour proposer un accompagnement packagé à nos clients. Certains grands comptes en France bénéficient déjà de ce partenariat et d’autres devraient suivre dans les prochains mois. » explique Frédéric Marie, Directeur Général de Stibo Systems France.
Revisiter son PRA grâce à Docker !
Comment revisiter son PRA grâce à Docker ?
Les infrastructures nécessitent bien sûr des sauvegardes régulières mais aussi une stratégie de récupération, pour parer à tout incident. C’est là qu’intervient le PRA.
Qu’est que e PRA ?
Cet acronyme, pas vraiment transparent, signifie « Plan de Reprise d’Activité ». C’est un plan qui permet de reconstruire l’infrastructure et de remettre en route les applications supportant l’activité d’une entreprise, en cas de crise majeure ou importante d’un centre informatique.
C’est un élément très important, à prendre en compte dès la conception et la mise en place d’une infrastructure.
Il faut toujours prévoir le pire et être capable de récupérer, dans un délai supportable, les données et les services de l’entreprise.
Il est par ailleurs essentiel d’être réaliste et pragmatique pour trouver le point d’équilibre entre perte de données ou de temps acceptable et coût du PRA !
Quelle est notre architecture ?
Nous avons une infrastructure hybride, à la fois physiquement présente dans nos locaux et sur des serveurs hébergés. Historiquement, des outils internes qui sont hébergés en local et des outils/environnements clients sur le Cloud.
Docker à Cantor ?
À Cantor, nous utilisons Docker depuis déjà plusieurs années.
Nous avons d’abord déployé de nouveaux services, et des environnements de développement sous Docker. Puis, progressivement, nous avons démarré une consolidation générale de nos infrastructures avec Docker. Le gain en terme de ressources matérielles et d’exploitation est significatif.
A ce jour, plus de la moitié des services et environnements sont déjà migrés.
Notre PRA « dockerisé »
A Cantor, nous avions déjà un PRA fonctionnel. Mais la consolidation de nos infrastructure avec Docker nous a donné l’opportunité de le repenser, afin de le rendre plus performant, en diminuant le délai et les actions à mener pour restaurer nos services et nos données sur une infrastructure de secours.
L’utilisation de Docker, loin d’être une contrainte, a été une force dans cette refonte de notre PRA.
En effet, une des spécificités de Docker est qu’il permet de réutiliser une configuration logicielle, même très complexe et multi-services, au travers d’ « images » et donc de relancer des services en quelques secondes.
Pour ce qui est des données, Docker propose l’utilisation des « volumes ». D’un point de vue technique, ces volumes peuvent être synchronisés rapidement et régulièrement depuis nos infrastructure vers des serveurs de secours.
Nous nous sommes servis de cette spécificité en l’automatisant, et sauvegardons désormais nos données plus régulièrement. La synchronisation est rapide car elle est incrémentale. Nous avons ainsi automatisé toute la chaîne de notre PRA. Nos données et nos services sont à l’abri et accessibles même après un dysfonctionnement de l’infrastructure.
Ainsi, dans le cas d’une défaillance d’infrastructure, les données sont déjà présentes au travers de volumes « mirrorés », les configurations logicielles sont prêtes au travers d' »images » Docker versionnées. Nous n’avons donc plus besoin de les récupérer !
Et nous pouvons relancer nos services en quelques minutes.
Et vous, êtes-vous prêts à ‘dockeriser’ votre PRA ?
Microanalyse embarquée pour un analyseur de plomb
Le FenX, analyseur de plomb
Le FEnX est le premier analyseur de plomb conçu et fabriqué en France.
Il est doté d’une source Cadmium 109 à faibles radiations.
Le FEnX est ergonomique, performant et innovant avec son écran tactile intuitif, son étalon de mesure intégré et son éclairage à LED.

Pour la réalisation de ce projet, Cantor a mis tout son savoir-faire et toute son expertise en microanalyse et en développements embarqués au service de Fondis.
Notre mission ?
Conception et développement, en environnement embarqué, de la chaîne d’acquisition temps-réel et implémentation des algorithmes de microanalyse de calcul de la concentration en Plomb.