Comment mettre en place un système centralisé de logs avec Docker et Ansible ?

Aujourd’hui, nous utilisons de nombreuses applications dans des buts très divers. De ce fait beaucoup d’échanges sont effectués entre les utilisateurs et les applications et même entre applications. Ce qui a pour effet de générer un nombre conséquent de logs. Ainsi avec la multiplication de ces échanges, les utilisateurs ne peuvent pas consulter manuellement toutes les applications pour consolider ces données.
L’idée était donc de mettre en place un système qui permettrait de simplifier ce processus de consultation pour toutes nos applications.
Ainsi à Cantor, étant donné que 90% de notre infrastructure est « dockerisée », nous avons décidé d’en profiter pour mettre en place un système centralisé afin d’optimiser notre temps de travail en réduisant les efforts nécessaires à la consultation fastidieuse des fichiers logs.
Pourquoi une simplification des fichiers logs ?
Ayant pour fonction le stockage des lignes d’informations générées par le serveur, la gestion des fichiers de logs est bien souvent contraignante, cependant il s’agit d’une source d’information précieuse, permettant la détection d’erreurs.
L’objectif était donc de ne plus aller consulter manuellement les fichiers journaux, ce qui impliquait de se connecter sur chaque machine, d’obtenir le lieu de stockage des fichiers logs de chaque application avant de pouvoir les consulter.
Pour simplifier cette gestion des logs, nous avons donc cherché à mettre en place un système centralisé et basé sur notre utilisation de Docker.
Quel système centralisé par Docker ?
Pour consolider les logs de toute une infrastructure dans une seule et unique application, Cantor a choisi d’intégrer une stack ELK avec Docker. Soit l’acronyme de trois projets open source : Elasticsearch, Logstash et Kibana.
En effet les composants ELK sont libres et gratuits, sans compter leur configuration simple et le fait qu’il n’y a pas d’impact applicatif. La mise à disposition de leur conteneur s’est intégrée parfaitement avec nos pratiques et nous avons de cette façon pu facilement mettre en place l’environnement.
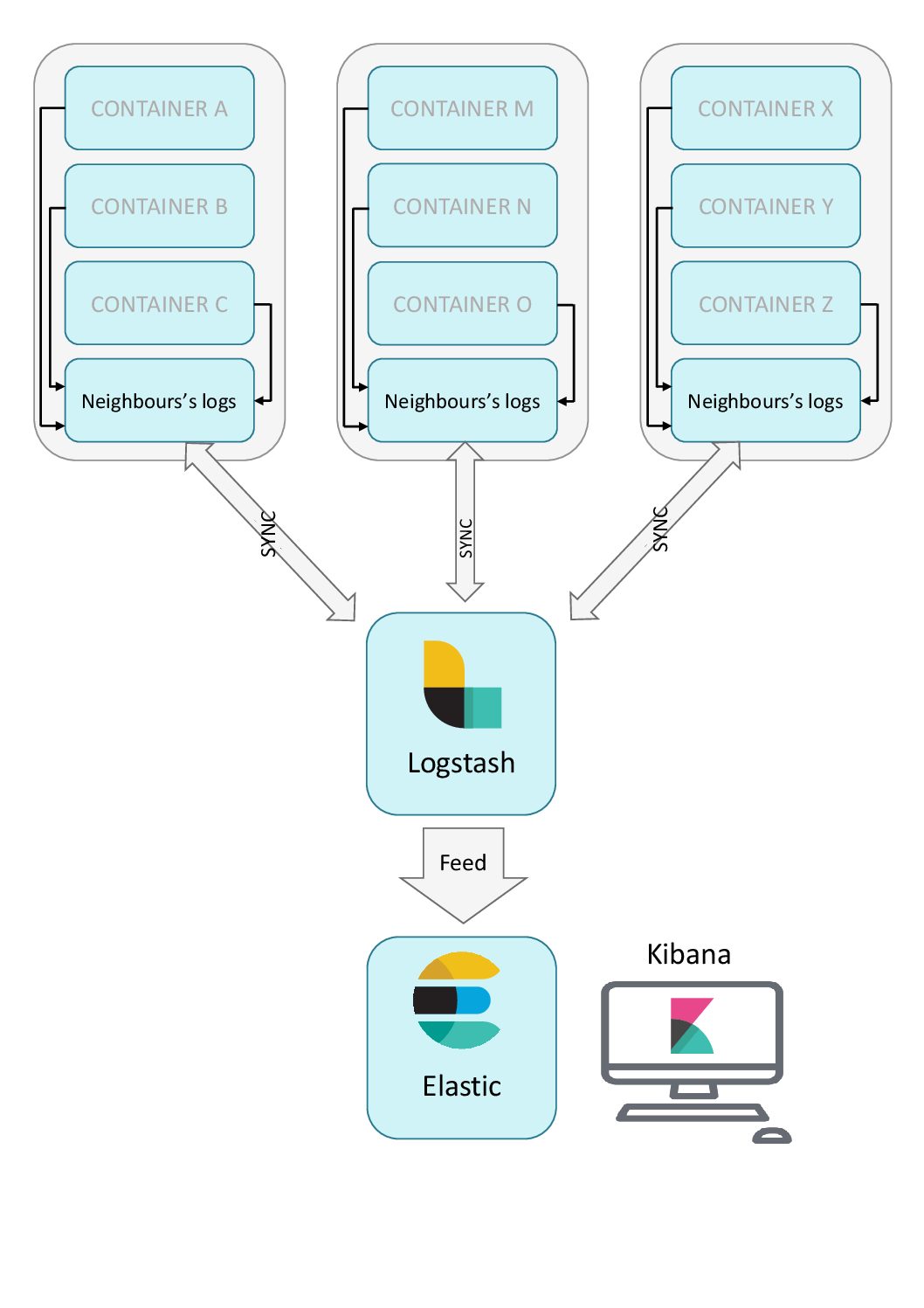
De façon plus détaillée, la stack ELK se trouve en bout de chaîne d’une centralisation à deux niveaux. Dans un premier temps, les méthodes de logging natives à Docker nous permettent de centraliser les logs sur un seul et même conteneur dans un voisinage réseau. C’est à ce stade que le deuxième niveau prend place, avec une synchronisation distante des logs auprès de chacun des conteneurs de premier niveau. Nous sommes alors capables d’obtenir l’intégralité de nos fichiers de logs de cette façon, qui sont ensuite indexés dans la stack ELK.
Un des avantages implicites de cette centralisation est l’économie d’espace disque. D’une part les logs ne sont plus stockés localement sur nos applications, et d’autre part la stack ELK possède un système de purge permettant de fixer nos règles de conservation des logs.
Quelle système d’automatisation avec Ansible ?
L’automatisation est aujourd’hui un élément essentiel de la transformation numérique.
En complément de Docker, nous utilisons donc Ansible pour orchestrer nos déploiements de conteneurs ou de configurations. Ce qui nous permet de configurer automatiquement nos machines pour les brancher sur notre chaîne de log.
Ainsi nous avons la capacité de déployer l’ensemble des containers de gestion de logs en une ligne de commande, que ce soit pour les containers locaux à chaque VM ou pour le cœur de la stack ELK mais aussi pour l’outillage en charge de rapatrier l’ensemble des logs de chaque VM.
L’automatisation avec Ansible a permis un gain de temps considérable et surtout d’éliminer les taches répétitives.
En somme, chez Cantor nous sommes capables de nous abstraire de la gestion des fichiers logs en mettant en place un système de centralisation à deux niveaux. A l’aide de Docker et Ansible, la totalité de notre infrastructure est concernée et branchée sur notre chaîne de logs et nous pouvons à tout moment les consulter au travers de tableaux de bords sur une seule et même interface de visualisation.

